























自动驾驶是一种使用计算机技术和传感器等设备使汽车或其他交通工具能够在没有人类司机干预的情况下自主驾驶的技术。基本原理是通过传感器(如激光雷达、摄像头、雷达等)实时感知识别车辆及周边环境(道路、交通标志、障碍物和其他交通参与者)等情况,再通过智能系统进行规划决策,最后通过控制系统执行驾驶操作。
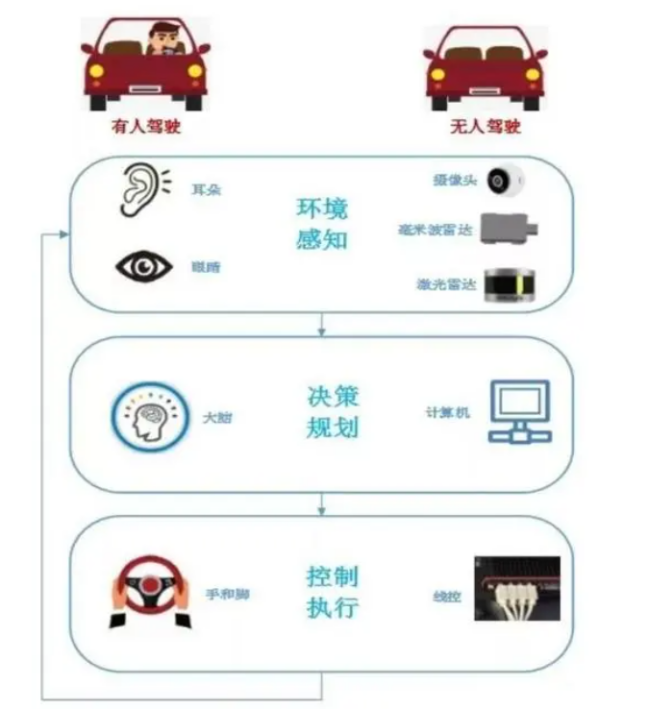
自动驾驶实现的过程,简单的来说是从感知、决策到执行,整个过程的实现对于人工智能(AI)/机器学习(ML)有着很深的应用和依赖。因此,自动驾驶发展的瓶颈主要在于这些AI算法模型上的突破。为了找到最佳的AI算法模型,算法工程师需要不断地调整超参数,对每天的路测数据进行处理,反复训练优化自动驾驶模型,并进行大量验证测试工作,以迭代出更准确的算法,这些工作的背后需要大量算力资源(GPU资源)。
自动驾驶训练带来的挑战
训练一个自动驾驶方案依赖大量的真实数据,数据采集车配备多个传感器进行数据采集,并将采集到的数据传输到深度学习GPU集群用于训练、学习以构建更智能的驾驶决策算法。数据采集车通常使用6-10个摄像头、4-6个雷达和2-4个激光雷达,它们都有不同的分辨率和距离范围,保守估算,一辆测试车每天产生的数据量可达 10 TB。
更大规模的数据集与更短的训练时间的诉求, 仅依靠单张 GPU、甚至单台 GPU 服务器已经无法满足自动驾驶 AI 训练的要求,多机多卡 GPU 计算集群成为必然选择。
另外,AI模型越庞大,模型参数越多,训练过程中的通信消耗也越大。一些大型 AI 模型的训练过程中,通信时间消耗占比已经超过 50%。在优化端到端的性能时,我们既需要考虑服务器内部的通信,也需要优化服务器外部的通信。


